Qu’est-ce qu’un modèle d’entraînement pour l'IA ?

L'essentiel à retenir
Un modèle d'entraînement est le cerveau numérique figé né d'un algorithme ayant digéré des données. En ajustant ses poids et biais, il transforme des statistiques brutes en décisions autonomes. Tu gagnes un temps massif en automatisant tes analyses pour te concentrer sur l'humain.
L'essentiel à retenir : un modèle d'entraînement est le cerveau numérique figé né d'un algorithme ayant digéré des données. En ajustant ses poids et biais, il transforme des statistiques brutes en décisions autonomes. Tu gagnes un temps massif en automatisant tes analyses pour te concentrer sur l'humain, notamment en comprenant l' utilité des modèles d'entraînement dans ton quotidien.
Sais-tu que la CNIL définit désormais le modèle d'IA comme une simple représentation statistique issue d'un apprentissage massif ? Tu as probablement déjà confondu l'algorithme, qui est la recette, avec le résultat final qui prend les décisions. Sans une structure claire, tu risques de te perdre dans des outils qui mémorisent tes données sans jamais rien comprendre.
On décortique ensemble qu’est-ce qu’un modèle d’entraînement pour transformer cette boîte noire en un assistant ultra-performant au service de ton activité quotidienne.
C'est quoi concrètement un modèle d'entraînement ?
Un modèle d'entraînement est le résultat figé d'un algorithme ayant digéré des données pour ajuster ses poids et biais. Cette représentation statistique permet de prédire des résultats ou d'automatiser des tâches complexes.
La structure interne du modèle, comparable à une mémoire vive, agit comme un cerveau numérique capable de transformer des informations brutes en décisions logiques.
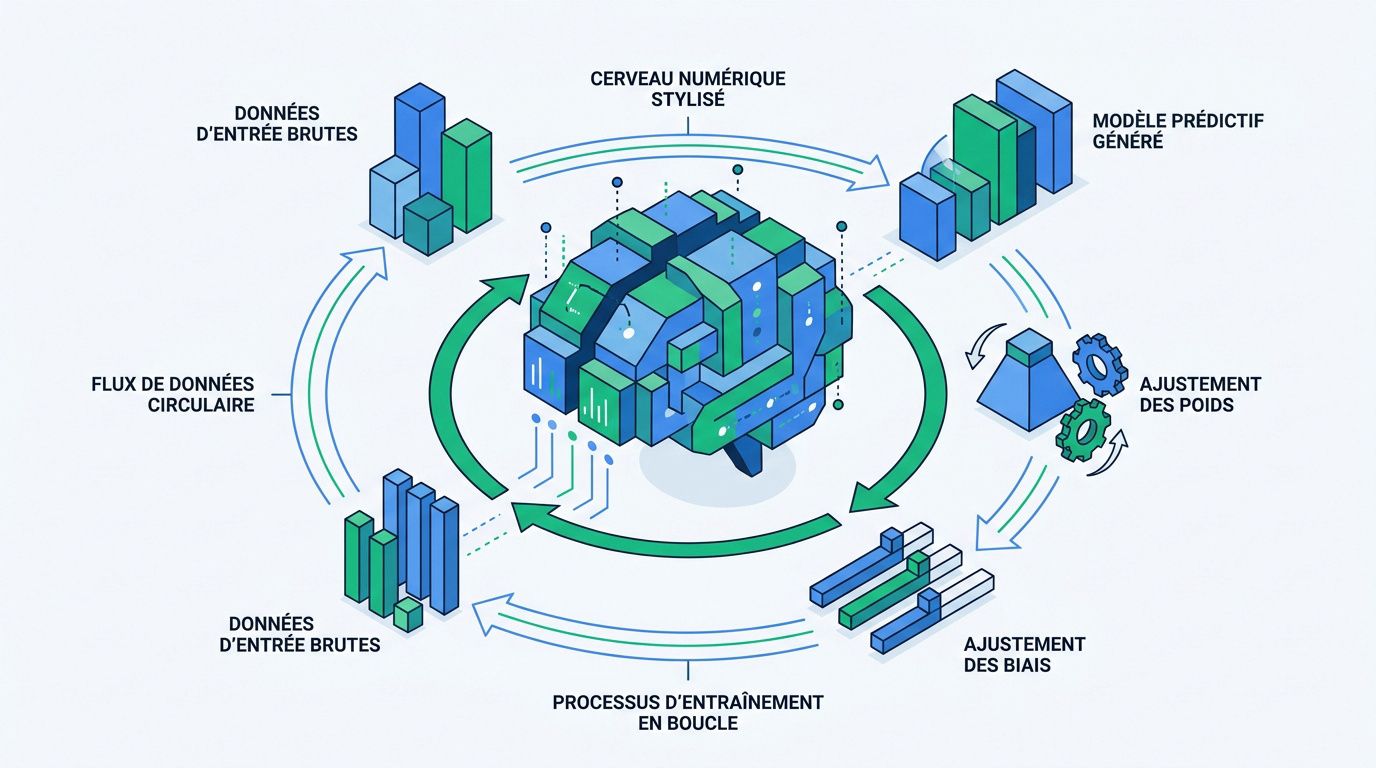
Un cerveau numérique sculpté par les données
Tu peux voir ça comme un athlète de haut niveau. Il répète ses gammes sans cesse pour créer des réflexes musculaires. Le modèle fait exactement la même chose avec tes données numériques.
Il ne stocke pas les fichiers bruts mais des schémas statistiques. C'est une connaissance pure, extraite et exploitable immédiatement. Le système ne mémorise pas, il apprend la structure logique profonde.
D'après la définition de la CNIL sur la représentation statistique, le modèle devient une archive de savoirs abstraits. C'est une synthèse mathématique du monde réel.
La distinction entre l'algorithme et le modèle
L'algorithme est ta recette de cuisine, le code informatique fixe. Le modèle, lui, est le plat final. C'est le résultat prêt à être dégusté par l'utilisateur final.
Tu peux découvrir l' utilité des modèles d'entraînement pour ton quotidien. Cette entité devient totalement autonome après sa phase de construction initiale.
Une fois figé, le modèle répond aux problèmes sans l'algorithme d'origine. Il n'a plus besoin du tuteur. Il est le produit fini de l'apprentissage machine.
C'est cette autonomie qui permet de l'intégrer facilement. Tu peux alors l'utiliser dans tes applications mobiles ou web pour coachs sportifs.
Le processus de création : de la donnée brute au résultat
Mais pour obtenir ce cerveau numérique, il faut d'abord passer par une phase de "nutrition" intense à base de données.
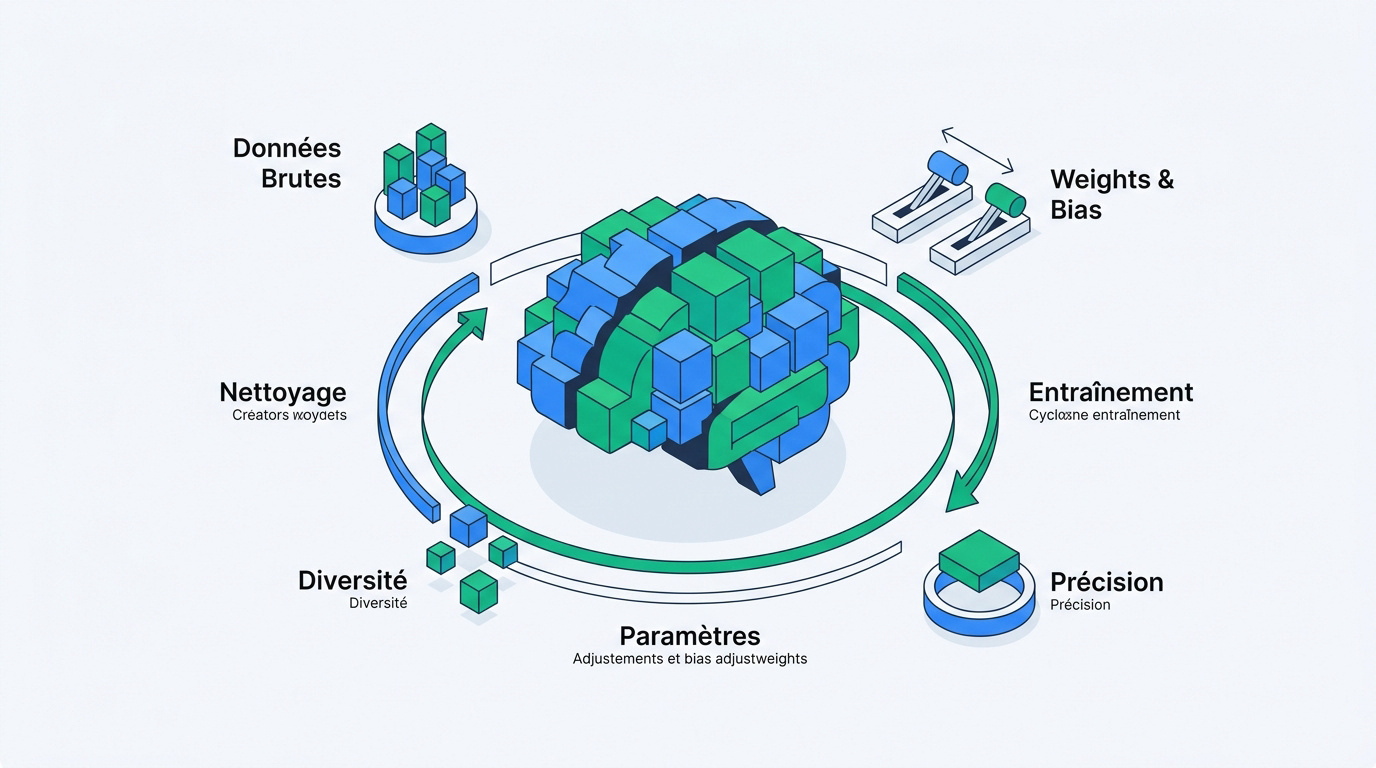
L'importance vitale d'un jeu de données propre
La qualité des données entrantes détermine la précision du modèle. Des données polluées entraînent des erreurs de jugement systématiques. C'est la base du travail.
La diversité est le rempart contre les biais. Il faut varier les profils pour éviter que le modèle ne devienne trop spécifique. Un bon échantillon est représentatif du réel.
Voici les éléments indispensables pour ton socle :
- Qualité des fichiers sources
- Diversité des profils utilisateurs
- Absence de doublons
- Étiquetage précis des informations
L'ajustement des paramètres pour viser juste
Le modèle ajuste ses poids et ses biais durant l'entraînement. Ces variables numériques sont les leviers de la précision. On cherche le réglage parfait.
Selon le processus d'optimisation des paramètres selon IBM, le cycle itératif permet au modèle de corriger ses propres erreurs de calcul. Tu affines ainsi la performance globale.
Chaque passage sur les données affine les résultats. C'est un travail de patience mathématique. Le score de réussite grimpe.
3 paradigmes pour apprendre aux machines à réfléchir
Alors, comment ces machines apprennent-elles réellement à faire ces choix ? Il existe trois grandes écoles de pensée.
Le mode supervisé contre l'auto-découverte
L'apprentissage supervisé utilise des étiquettes claires. On donne la réponse à l'algorithme pour qu'il apprenne la règle. C'est une méthode très efficace.
À l'inverse, l'auto-découverte (non supervisé) cherche des liens cachés. Le modèle regroupe les données par similarité sans aide humaine. C'est utile pour segmenter une clientèle.
Pour récolter ces données, il est crucial de maîtriser la définition d'un formulaire sportif afin de comprendre l'étiquetage. C'est la base pour ton futur modèle.
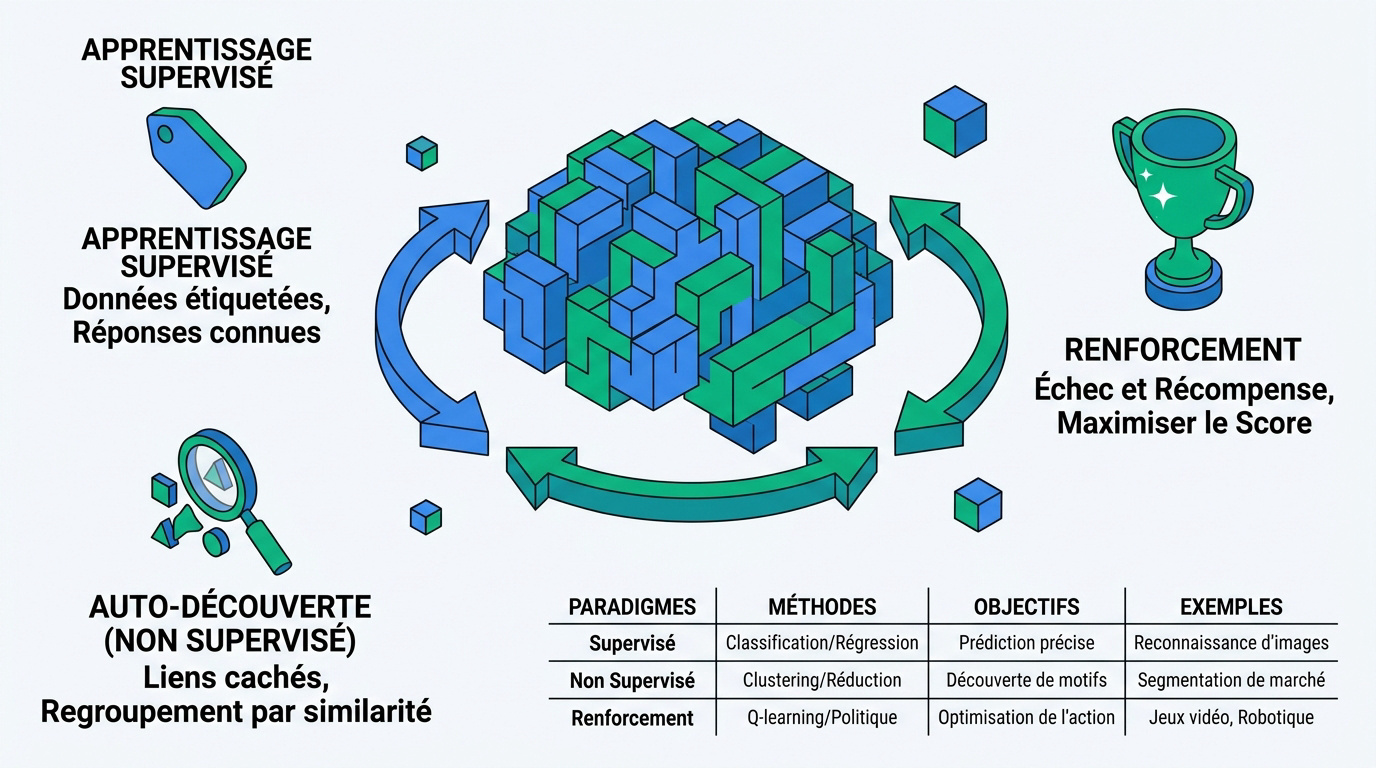
Le renforcement : apprendre par l'échec et la récompense
Le renforcement fonctionne comme un jeu vidéo. Le modèle reçoit des points s'il réussit une action. Il perd des points en cas d'échec.
Cette méthode pousse à l'exploration de l'environnement. Le modèle teste des stratégies pour maximiser son score final. C'est idéal pour la planification complexe.
| Paradigme | Méthode | Objectif | Exemple |
|---|---|---|---|
| Supervisé | Données étiquetées | Prédire une sortie | Détection de spam |
| Non supervisé | Données brutes | Trouver des motifs | Segmentation clients |
| Renforcement | Essais et erreurs | Maximiser les gains | Jeux vidéo (AlphaGo) |
← Faites défiler horizontalement pour voir toutes les colonnes →
Généralisation et performance : le test de vérité
Pourtant, avoir un bon score sur le papier ne suffit pas. Le vrai test se passe sur le terrain, face à l'imprévu.
Éviter le surapprentissage pour rester efficace
Le surapprentissage est le piège de la mémoire. Le modèle retient les données par cœur au lieu de comprendre la logique. Il devient alors inutile pour tes prédictions futures.
La flexibilité prime sur la perfection pure. Un bon modèle doit savoir s'adapter à des situations inconnues. C'est ce qu'on appelle la capacité de généralisation, essentielle pour tes résultats.
Il est intéressant de découvrir ce qu'est le coaching hybride pour voir l'application de modèles flexibles. Ces outils s'adaptent enfin à la réalité changeante de tes élèves au quotidien.
L'utilité réelle dans ton quotidien de pro
Ces concepts permettent d'automatiser les tâches pénibles. La prédiction de données aide à personnaliser le suivi des élèves. C'est un gain de temps massif pour ton activité de coach.
Un coach peut ainsi se concentrer sur l'humain. Le modèle gère l'analyse des tendances et les alertes automatiques. La technologie devient un assistant invisible mais puissant pour ta performance.
- Gain de temps administratif
- Personnalisation accrue
- Analyse prédictive des progrès
- Automatisation des rappels
Ton modèle d’entraînement transforme tes données brutes en un cerveau numérique capable de prédire tes résultats futurs. En ajustant ses poids et biais, il automatise tes tâches complexes pour booster ta productivité immédiate. Maîtrise ces schémas statistiques dès maintenant pour dominer ton marché grâce à une précision décisionnelle absolue.
C'est quoi exactement un modèle d'entraînement en IA ?
C'est quoi exactement un modèle d'entraînement en IA ?
C'est le cerveau numérique issu de ton travail. Concrètement, c'est le résultat final obtenu après qu'un algorithme a digéré des tonnes de données pour apprendre à repérer des schémas. Contrairement à l'algorithme qui est une simple recette, le modèle est le plat prêt à être servi : un programme capable de prédire des résultats ou d'automatiser tes tâches complexes instantanément.
Quelle est la différence entre un algorithme et un modèle ?
Quelle est la différence entre un algorithme et un modèle ?
Ne confonds plus les deux ! L'algorithme est la procédure mathématique, le code qui définit comment apprendre. Le modèle, lui, est le produit fini, l'entité qui possède la connaissance. Pour faire simple : l'algorithme est l'entraînement intensif d'un athlète, tandis que le modèle représente ses réflexes et sa performance le jour de la compétition.
Comment se passe l'entraînement d'un modèle ?
Comment se passe l'entraînement d'un modèle ?
C'est un processus itératif de précision chirurgicale. On injecte des données à l'algorithme qui ajuste ses poids et ses biais (ses leviers internes) pour réduire ses erreurs. Le but est d'optimiser ces paramètres jusqu'à obtenir un score de réussite maximal. C'est une véritable sculpture mathématique où chaque passage sur les données affine la décision finale.
Pourquoi la qualité des données est-elle si cruciale ?
Pourquoi la qualité des données est-elle si cruciale ?
C'est la règle d'or : si tu donnes des déchets en entrée, tu obtiendras des erreurs en sortie. Des données propres, diversifiées et étiquetées avec soin sont le carburant d'un modèle performant. Sans un jeu de données représentatif du monde réel, ton modèle sera biaisé et totalement inefficace face à de nouveaux utilisateurs.
C'est quoi le surapprentissage ou 'overfitting' ?
C'est quoi le surapprentissage ou 'overfitting' ?
C'est le piège de la mémoire pure. Le modèle apprend tes données par cœur, incluant les bruits et les erreurs, au lieu de comprendre la logique globale. Résultat ? Il est excellent sur tes tests mais s'effondre face à l'imprévu. Un bon modèle doit rester flexible pour généraliser son savoir à n'importe quelle situation nouvelle.
À quoi servent les poids et les biais dans l'IA ?
À quoi servent les poids et les biais dans l'IA ?
Ce sont les variables magiques de ton modèle. Les poids déterminent l'importance de chaque information, comme une mémoire vive qui hiérarchise les signaux. Les biais permettent d'ajuster la sensibilité du modèle pour qu'il colle parfaitement à la réalité. Ensemble, ils forment la structure de décision qui rend ton assistant virtuel intelligent et réactif.
Quels sont les différents modes d'apprentissage ?
Quels sont les différents modes d'apprentissage ?
Il existe trois écoles majeures : le supervisé (on donne les réponses pour apprendre la règle), le non supervisé (le modèle découvre seul des liens cachés) et le renforcement (apprentissage par l'échec et la récompense). Chaque méthode répond à un besoin spécifique, de la segmentation de tes clients à la planification de stratégies complexes.





